
이 글은 유튜브 '자바의 정석 - 기초편'을 보고 정리한 글입니다.
📂content
1. 스트림의 연산 - 중간 연산
| 중간 연산 | 설명 | |
| Stream<T> distinct() | 중복을 제거 | |
| Stream<T> filter(Predicate<T> predicate) | 조건에 안 맞는 요소 제외 | |
| Stream<T> limit(long maxSize) | 스트림의 일부를 잘라낸다 | |
| Stream<T> skip(long n) | 스트림의 일부를 건너뛴다. | |
| Stream peek(Consumer action) | 스트림의 요소에 작업 수행 => 작업 중간에 잘 처리되었는지 확인할 때 많이 쓴다. |
|
| Stream<T> sorted() Stream<T> sorted(Comparator<? super T> comparator) |
스트림의 요소를 정렬한다. | |
Stream<R> DoubleStream IntStream LongStream Stream<R> DoubleStream IntStream LongStream |
map(Function<T, R> mapper) mapToDouble(ToDoubleFunction<T> mapper) mapToInt(ToIntFunction<T> mapper) mapToLong(ToLongFunction<T> mapper) flatMap(Function<T, Stream<R>> mapper) flatMapToDouble(Function<T, DoubleStream> m) flatMapToInt(Function<T, IntStream> m) flatMapToLong(Function<T, LongStream> m) |
스트림의 요소를 변환한다. |
① 스트림 자르기 - limit(), skip()
Stream<T> skip(long n) // 앞에서부터 n개 건너뛰기
Stream<T> limit(long maxSize) // maxSize 이후의 요소는 잘라냄
intStream.skip(3).limit(5).forEach(System.out::print); // 45678
② 스트림의 요소 걸러내기 - filter(), distinct()
Stream<T> filter(Predicate<T> predicate) // 조건에 맞지 않는 요소 제거
Stream<T> distinct() // 중복 제거
IntStream intStream = IntStream.of(1,2,2,3,3,3,4,5,5,6);
intStream.distinct().forEach(System.out::print); // 123456
IntStream intStream = IntStream.rangeClosed(1, 10); // 12345678910
//2의 배수만 통과
intStream.filter(i->i%2==0).forEach(System.out::print); // 246810
intStream.filter(i->i%2!=0 && i%3!=0).forEach(System.out::print);
// 필터 여러 번 사용 가능
intStream.filter(i->i%2!=0).filter(i->i%3!=0).forEach(System.out::print);
③ 스트림 정렬하기 - sorted
Stream<T> sorted() //스트림 요소의 기본 정렬(Comparable)로 정렬
Stream<T> sorted(Comparator<? super T> comparator) //지정된 Comparator로 정렬
정렬시 필요한 것이 2가지가 있다. 1. 정렬 대상, 2. 정렬기준이 필요하다. Comparator가 정렬기준이다. 이것을 안 주면 스트림 요소가 기본정렬을 갖고 있어야 한다. 즉, Comparable로 정렬을 한다.
그런데 만약 Comparable을 갖고 있지 않다면 Comparator로 정렬한다.
| 문자열 스트림 정렬 방법 Stream<String> strStream = Stream.of("dd","aaa","CC","cc","b"); |
출력 결과 |
| strStream.sorted() // 기본 정렬 strStream.sorted(Comparator.naturalOrder()) // 기본 정렬 strStream.sorted((s1, s2) -> s1.compareTo(s2)); // 람다식도 가능 strStream.sorted(String::compareTo); // 위의 문장과 동일(메서드참조) |
CCaaabccdd |
| strStream.sorted(Comparator.reverseOrder()) // 기본 정렬의 역순 strStream.sorted(Comparator.<String>naturalOrder().reversed()) |
ddccbaaaCC |
| strStream.sorted(String.CASE_INSENSITIVE_ORDER) //대소문자 구분 안 함 | aaabCCccdd |
| strStream.sorted(String.CASE_INSENSITIVE_ORDER.reversed()) // 결과 오타 아님. 대문자 먼저 나옴 |
ddCCccbaaa |
| strStream.sorted(Comparator.comparing(String::length)) //길이 순 정렬 strStream.sorted(Comparator.comparingInt(String::length)) // no오토박싱 |
bddCCccaaa |
| strStream.sorted(Comparator.comparing(String::length).reversed()) | aaaddCCccb |
- compareTo()는 인스턴스 메소드이다. 그래서 앞에 참조변수가 있어야 한다.
참조변수.compareTo(매개변수) 그래서 입력이 2개가 필요하다.
따라서 람다식을 작성할 때 s1,s2가 되는 것이다.
- CASE_INSENSITIVE_ORDER는 Comparator이다.
static Comparator<String> CASE_INSENSITIVE_ORDER = new CaseInsensitiveComparator();자주 사용이 되므로 미리 만들어놓은 것. 이것은 대소문자 구별을 안 한다는 것이다.
⚝ Comparator의 comparing()으로 정렬 기준을 제공
comparing(Function<T, U> keyExtractor)
comparing(Function<T, U> keyExtractor, Comparator<U> keyComparator)
studentStream.sorted(Comparator.comparing(Student::getBan)) //반별로 정렬. 메서드 참조
.forEach(System.out::println);
Stream<T> sorted(Comparator comparator)는 Comparator을 필요로 한다.
그리고 comparing의 반환타입이 Comparator이다. 그래서 sorted매개변수로 Comparator.comparing을
넣는 것이다.
⚝ 추가 정렬 기준을 제공할 때는 thenComparing()을 사용
thenComparing(Comparator<T> other)
thenComparing(Function<T, U> keyExtractor)
thenComparing(Function<T, U> keyExtractor, Comparator<U> keyComp)
studentStream.sorted(Comparator.comparing(Student::getBan) //반별로 정렬
.thenComparing(Student::getTotalScore) //총점별로 정렬
.thenComparing(Student::getName)) //이름별로 정렬
.forEach(System.out::println);
⍟실습
Ex14_5
import java.util.*;
import java.util.stream.*;
class Ex14_5 {
public static void main(String[] args) {
Stream<Student> studentStream = Stream.of(
new Student("이자바", 3, 300),
new Student("김자바", 1, 200),
new Student("안자바", 2, 100),
new Student("박자바", 2, 150),
new Student("소자바", 1, 200),
new Student("나자바", 3, 290),
new Student("감자바", 3, 180)
);
studentStream.sorted(Comparator.comparing(Student::getBan) // 반별 정렬
//Comparator.comparing(Student::getBan).reversed() // 역순 정렬
//Comparator.comparing((Student s) -> s.getBan()) // 람다식
.thenComparing(Comparator.naturalOrder())) // 기본 정렬
//Comparator.naturalOrder().reversed() // 역순 정렬
.forEach(System.out::println);
}
}
class Student implements Comparable<Student> {
String name;
int ban;
int totalScore;
Student(String name, int ban, int totalScore) {
this.name =name;
this.ban =ban;
this.totalScore =totalScore;
}
public String toString() {
return String.format("[%s, %d, %d]", name, ban, totalScore);
}
String getName() { return name;}
int getBan() { return ban;}
int getTotalScore() { return totalScore;}
// 총점 내림차순을 기본 정렬로 한다.
public int compareTo(Student s) {
return s.totalScore - this.totalScore;
}
}
④ 스트림의 요소 변환하기 - map()
Stream<R> map(Function<? super T, ? extends R> mapper) //Stream<T> -> Stream<R>
Stream<File> fileStream = Stream.of(new File("Ex1.java"), new File("Ex1")
new File("Ex1.bak"), new File("Ex2.java"), new File("Ex1.txt"));
Stream<String> filenameStream = fileStream.map(File::getName);
filenameStream.forEach(System.out::println); // 스트림의 모든 파일의 이름을 출력
- Stream T가 Stream R로 바뀐다는 것을 알아두자!
- File Stream을 map()을 이용해서 String Stream으로 바꾼다. File 객체를 주면 getName()을 호출해서 String을 반환한다. fileStream.map(File::getName);을 람다식을 바꾸면 (File f) -> f.getName();이다.
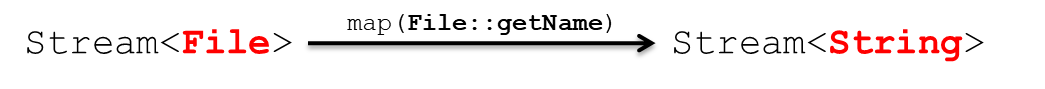
예) 파일 스트림(Stream<File>)에서 파일 확장자(대문자)를 중복없이 뽑아내기
fileStream.map(File::getName) // Stream → Stream
.filter(s->s.indexOf('.')!=-1) // 확장자가 없는 것은 제외
.map(s->s.substring(s.indexOf('.')+1)) // Stream→Stream
.map(String::toUpperCase) // Stream→Stream
.distinct() // 중복 제거
.forEach(System.out::print); // JAVABAKTXT
⍟실습
Ex14_6
import java.io.*;
import java.util.stream.*;
class Ex14_6 {
public static void main(String[] args) {
File[] fileArr = { new File("Ex1.java"), new File("Ex1.bak"),
new File("Ex2.java"), new File("Ex1"), new File("Ex1.txt")
};
Stream<File> fileStream = Stream.of(fileArr);
// map()으로 Stream<File>을 Stream<String>으로 변환
// 메서드 참조가 이해가 안 되면 람다식으로 바꾸기
//fileStream.map((File f) -> f.getName());
Stream<String> filenameStream = fileStream.map(File::getName);
filenameStream.forEach(System.out::println); // 모든 파일의 이름을 출력
fileStream = Stream.of(fileArr); // 스트림을 다시 생성
fileStream.map(File::getName) // Stream<File> → Stream<String>
.filter(s -> s.indexOf('.')!=-1) // 확장자가 없는 것은 제외
.map(s -> s.substring(s.indexOf('.')+1)) // 확장자만 추출
.map(String::toUpperCase) // 모두 대문자로 변환
.distinct() // 중복 제거
.forEach(System.out::print); // JAVABAKTXT
System.out.println();
}
}
⑤ 스트림의 요소를 소비하지 않고 엿보기 - peek()
Stream<T> peek(Consumer<? super T> action) // 중간 연산(스트림을 소비X)
void forEach(Consumer<? super T> action) // 최종 연산(스트림을 소비O)
fileStream.map(File::getName) // Stream<File> → Stream<String>
.filter(s -> s.indexOf('.')!=-1) // 확장자가 없는 것은 제외
.peek(s->Systehttp://m.out.printf("filename=%s%n", s)) // 파일명을 출력한다.
.map(s -> s.substring(s.indexOf('.')+1)) // 확장자만 추출
.peek(s->Systehttp://m.out.printf("extension=%s%n", s)) // 확장자를 출력한다.
.forEach(System.out::println); // 최종연산 스트림을 소비.
- peek는 사실 forEach와 같다. 그런데 peek은 중간연산이라 스트림의 요소를 소비하지 않는다. 하지만 forEach는 최종연산이라 스트림의 요소를 꺼내서 소비한다. 그래서 forEach의 반환값은 void인 것이다.
- peek는 중간작업 결과를 확인할 때 사용된다. (디버깅 용도)
⑥ 스트림의 스트림을 스트림으로 변환 - flatMap()
Stream<String[]> strArrStrm = Stream.of(new String[]{"abc", "def", "ghi" },
new String[]{"ABC", "GHI", "JKLMN"});
Stream<Stream<String>> strStrStrm = strArrStrm.map(Arrays::stream);
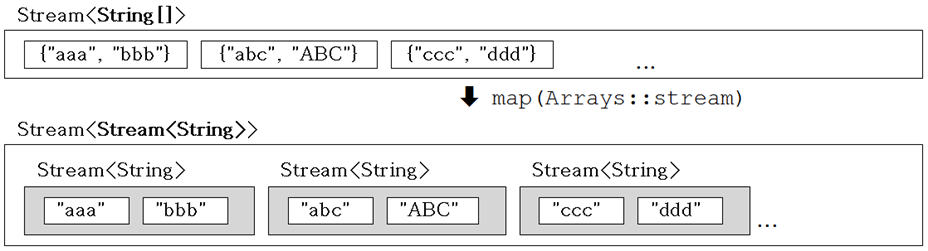
- 위 코드를 보면 String배열이 Stream으로 되어있다. 이 말은 Stream의 요소 하나가 String배열이라는 것이다.
- 이것을 map을 이용해서 변환을 하면 Stream<String[]>이 Stream<String>으로 변한다.
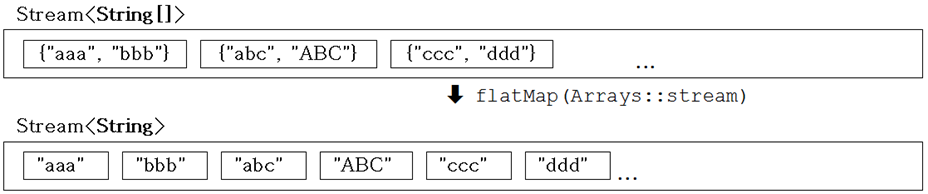
하지만 개발자가 원한 것이 <그림6-1>결과가 아닌 <그림6-2>의 결과라고 하자
그럼 어떤 코드를 작성해야 할까?
flatMap을 이용한다!
- <그림6-2>처럼 문자열의 배열들을 하나로 합치고 싶다. 다시말하자면, 여러 개의 문자열 배열을 하나의 문자열 배열인 것처럼 만드는 것이다.
Stream<String> strStrStrm = strArrStrm.flatMap(Arrays::stream); // Arrays.stream(T[])
⍟실습
Ex14_7
import java.util.*;
import java.util.stream.*;
class Ex14_7 {
public static void main(String[] args) {
Stream<String[]> strArrStrm = Stream.of(
new String[]{"abc", "def", "jkl"},
new String[]{"ABC", "GHI", "JKL"}
);
// Stream<Stream<String>> strStrmStrm = strArrStrm.map(Arrays::stream);
Stream<String> strStrm = strArrStrm.flatMap(Arrays::stream);
strStrm.map(String::toLowerCase) //스트림의 요소를 모두 소문자로 변경
.distinct() //중복제거
.sorted() //정렬
.forEach(System.out::println);
System.out.println();
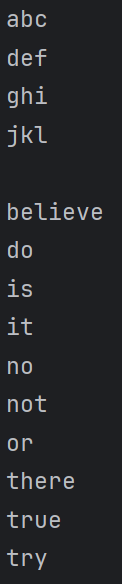
String[] lineArr = {
"Believe or not It is true",
"Do or do not There is no try",
};
Stream<String> lineStream = Arrays.stream(lineArr);
lineStream.flatMap(line -> Stream.of(line.split(" +")))
.map(String::toLowerCase)
.distinct()
.sorted()
.forEach(System.out::println);
System.out.println();
}
}
- 만약 flatMap()이 아닌 map()을 사용한다면 결과값으로 `java.util.stream.ReferencePipeline$Head@주소값`이 나온다.
- `line.split(" +")`에서 " +"은 정규식이다. 하나 이상의 공백을 의미한다. " "은 공백인데 +를 사용하면서 하나 이상이 된다.
2. 스트림의 연산 - 최종 연산
| 최종 연산 | 설명 |
| void forEach(Consumer<? super T> action) void forEachOrdered(Consumer<? super T> action) //순서유지 |
각 요소에 지정된 작업 수행 +) forEachOrdered는 병렬스트림일때 작업순서를 유지할 때 사용. 병렬이 아닌 경우는 상관x |
| long count() | 스트림의 요소의 개수 반환 |
| Optional<T> max(Comparator<? super T> comparator) Optional<T> min(Comparator<? super T> comparator) |
스트림의 최대값/최소값을 반환 |
| Optional<T> findAny() //아무거나 하나 //병렬 Optional<T> findFirst() //첫 번째 요소 //직렬 |
스트림의 요소 하나를 반환 +) filter()와 같이 쓰인다. |
| boolean allMatch(Predicate<T> p) //모두 만족하는지 boolean anyMatch(Predicate<T> p) // 하나라도 만족하는지 boolean noneMatch(Predicate<T> p) // 모두 만족하지 않는지 |
주어진 조건을 모든 요소가 만족시키는지, 만족시키지 않는지 확인 |
| Object[] toArray() A[] toArray(IntFunction<A[]> generator) |
스트림의 모든 요소를 배열로 반환 |
| Optional<T> reduce(BinaryOperator<T> accumulator) T reduce(T identity, BinaryOperator<T> accumulator) U reduce(U identity, BiFunction<U, T, U> accumulator, BinaryOperator<U> combiner) |
스트림의 요소를 하나씩 줄여가면서(리듀싱) 계산한다. +) sum(), count()같은 계산을 할 때 |
| R collect(Collector<T, A, R> collector) R collect(Supplier<R> supplier, BiConsumer<R, T> accumulator, BiConsumer<R,R> combiner) |
스트림의 요소를 수집한다. 주로 요소를 그룹화하거나 분할한결과를 컬렉션에 담아 반환하는데 사용된다. |
reduce를 잘 이해하는 것이 핵심!
① 스트림의 모든 요소에 지정된 작업을 수행 - forEach(), forEachOrdered()
void forEach(Consumer<? super T> action) // 병렬스트림인 경우 순서가 보장되지 않음
void forEachOrdered(Consumer<? super T> action) // 병렬스트림인 경우에도 순서가 보장됨
IntStream.range(1, 10).sequential().forEach(System.out::print); // 123456789
IntStream.range(1, 10).sequential().forEachOrdered(System.out::print); // 123456789
IntStream.range(1, 10).parallel().forEach(System.out::print); // 683295714
IntStream.range(1, 10).parallel().forEachOrdered(System.out::print); // 123456789
sequential()은 스트림의 작업을 직렬로 처리하는 직렬 스트림이고,
parallel()은 스트림의 작업을 병렬로 처리하는 병렬 스트림이다. 이건 여러 스레드가 나누어서 작업하는 것이다.
기본적으로 스트림은 직렬이라서 sequential()은 생략해도 된다.
그리고 parallel()을 사용하면 여러 스레드가 돌아가기 때문에 순서가 보장이 안 된다. 그래서 sequential()을 사용하면 123456789와 같은 결과가 나오는데 parallel()을 사용하면 683295714같은 결과가 나오는 것이다. 즉, 순서 보장이 안 된다. 그런데 여기서 또 forEachOrdered를 사용하면 순서가 보장이 된다.
forEachOrdered를 사용하면 성능이 forEach를 사용할 때보다 떨어진다. 순서를 보장해야하기 때문에.
② 조건 검사 - allMatch(), anyMatch(), noneMatch()
boolean allMatch (Predicate<? super T> predicate) // 모든 요소가 조건을 만족시키면 true
boolean anyMatch (Predicate<? super T> predicate) // 한 요소라도 조건을 만족시키면 true
boolean noneMatch(Predicate<? super T> predicate) // 모든 요소가 조건을 만족시키지 않으면 true
boolean hasFailedStu = stuStream.anyMatch(s-> s.getTotalScore()<=100); // 낙제자가 있는지?
③ 조건에 일치하는 요소 찾기 - findFirst(), findAny()
Optional<T> findFirst() // 첫 번째 요소를 반환. 순차 스트림에 사용
Optional<T> findAny() // 아무거나 하나를 반환. 병렬 스트림에 사용
Optional<Student> result = stuStream.filter(s-> s.getTotalScore() <= 100).findFirst();
Optional<Student> result = parallelStream.filter(s-> s.getTotalScore() <= 100).findAny();
filter랑 같이 사용된다.
④ 스트림의 요소를 하나씩 줄여가며 누적연산 수행 - reduce()
Optional<T> reduce(BinaryOperator<T> accumulator)
T reduce(T identity, BinaryOperator<T> accumulator)
U reduce(U identity, BiFunction<U,T,U> accumulator, BinaryOperator<U> combiner)
• identity - 초기값
• accumulator - 이전 연산결과와 스트림의 요소에 수행할 연산
• combiner - 병렬처리된 결과를 합치는데 사용할 연산(병렬 스트림)
reduce()는 여러가지 오버로딩 되어있는데, identity와 accumulator가 핵심이다.
// int reduce(int identity, IntBinaryOperator op) => reduce(초기값, 수행할 연산)
int count = intStream.reduce(0, (a,b) -> a + 1); // count()
int sum = intStream.reduce(0, (a,b) -> a + b); // sum()
/*
윗 줄이 내부적으로 이와 같이 돌아간다.
int a = identity; //초기값
for(int b : stream)
a = a + b; // sum() 수행할 연산
*/
int max = intStream.reduce(Integer.MIN_VALUE,(a,b)-> a > b ? a : b); // max()
int min = intStream.reduce(Integer.MAX_VALUE,(a,b)-> a < b ? a : b); // min()
// OptionalInt reduce(IntBinaryOperator accumulator)
OptionalInt max = intStream.reduce((a,b) -> a > b ? a : b); // max()
OptionalInt min = intStream.reduce((a,b) -> a < b ? a : b); // min()
OptionalInt max = intStream.reduce(Integer::max); // static int max(int a, int b)
OptionalInt min = intStream.reduce(Integer::min); // static int min(int a, int b)
⍟실습
Ex14_9
import java.util.*;
import java.util.stream.*;
class Ex14_9 {
public static void main(String[] args) {
String[] strArr = {
"Inheritance", "Java", "Lambda", "stream",
"OptionalDouble", "IntStream", "count", "sum"
};
Stream.of(strArr).forEach(System.out::println);
//Stream.of(strArr).parallel().forEach(System.out::println);
//병렬로 처리하면 실행할 때마다 순서가 바뀐다. 여러 스레드가 처리하기때문이다.
//그런데 병렬로 처리하는데도 순서를 유지하고 싶다면 forEachOrdered를 사용한다.
boolean noEmptyStr = Stream.of(strArr).noneMatch(s->s.length()==0);
Optional<String> sWord = Stream.of(strArr)
.filter(s->s.charAt(0)=='s').findFirst();
System.out.println("noEmptyStr="+noEmptyStr);
System.out.println("sWord="+ sWord.get());
// Stream<String>을 IntStream으로 변환. (s) -> s.length()
// Stream<Integer> intStream1 = Stream.of(strArr).map(String::length);
// Stream<String>을 IntStream으로 변환. IntStream 기본형 스트림
IntStream intStream1 = Stream.of(strArr).mapToInt(String::length);
IntStream intStream2 = Stream.of(strArr).mapToInt(String::length);
IntStream intStream3 = Stream.of(strArr).mapToInt(String::length);
IntStream intStream4 = Stream.of(strArr).mapToInt(String::length);
int count = intStream1.reduce(0, (a,b) -> a + 1);
int sum = intStream2.reduce(0, (a,b) -> a + b);
OptionalInt max = intStream3.reduce(Integer::max);
OptionalInt min = intStream4.reduce(Integer::min);
System.out.println("count="+count);
System.out.println("sum="+sum);
System.out.println("max="+ max.getAsInt());
System.out.println("min="+ min.getAsInt());
}
}
출처
'🎥Back > 자바의 정석' 카테고리의 다른 글
| [JAVA의 정석]Optional (0) | 2024.03.09 |
|---|---|
| [JAVA의 정석] 스트림 (0) | 2024.03.08 |
| [JAVA의 정석]람다식과 함수형 인터페이스 (2) | 2024.03.06 |
| [JAVA의 정석] 스레드와 관련된 함수 및 동기화 (0) | 2024.03.01 |
| [JAVA의 정석]데몬 스레드, 스레드의 상태 (0) | 2024.02.29 |